We built our own BugBot, but better
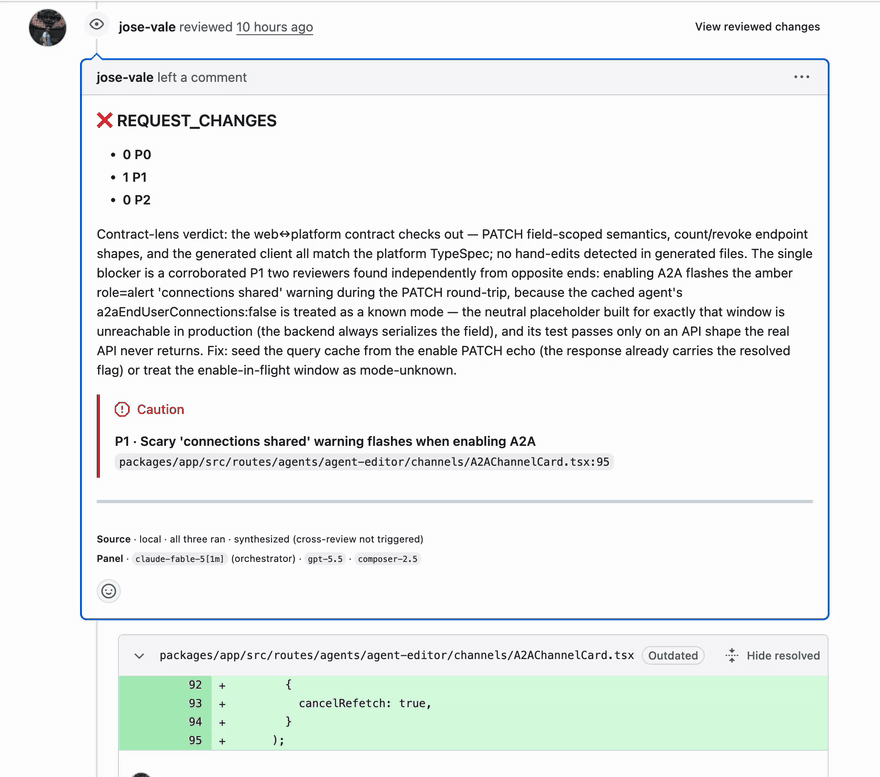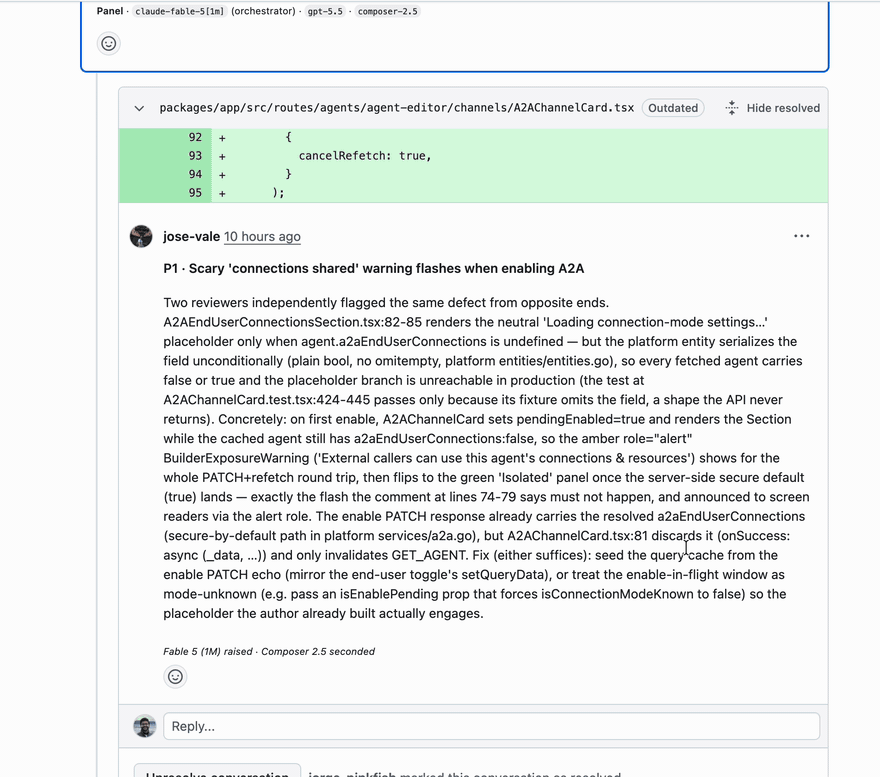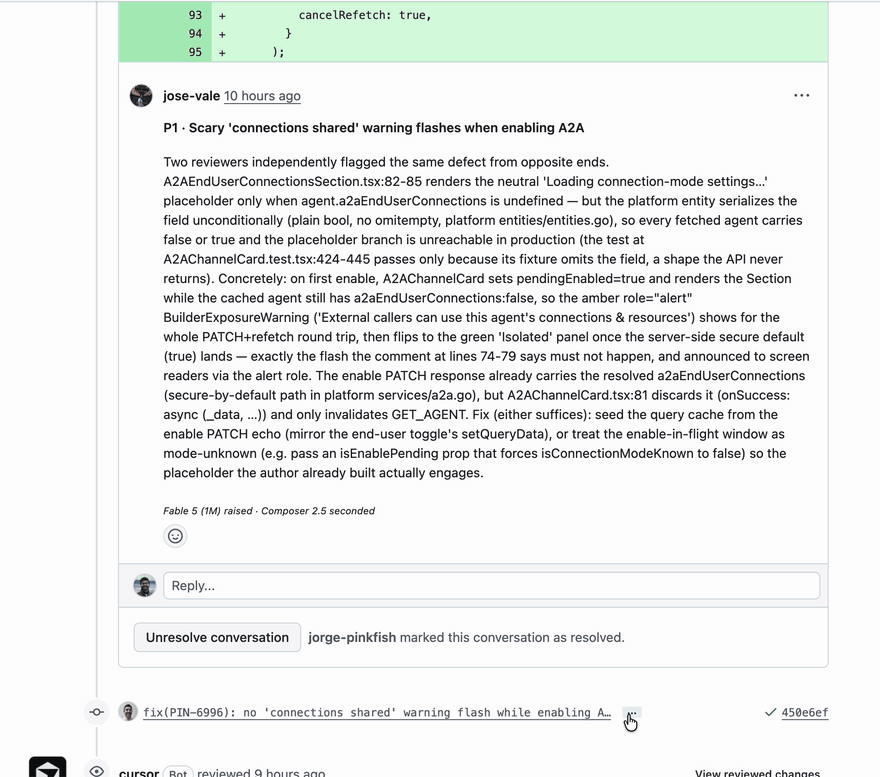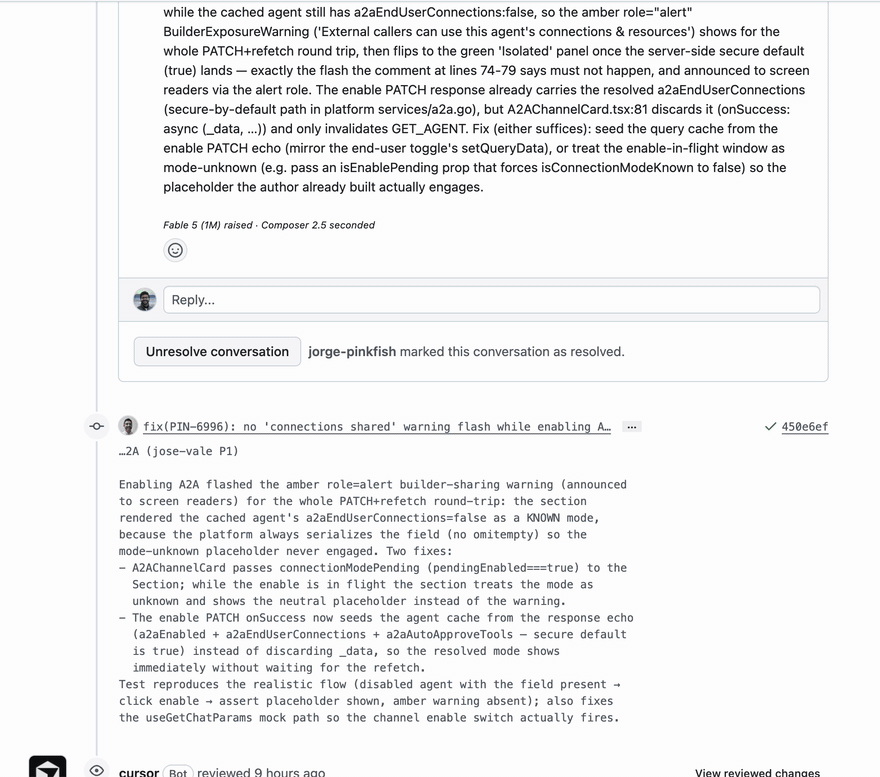
We have been using Cursor's BugBot since the day it launched, over a year ago. It is a required check on every pull request we merge. But a year of heavy use taught us its one maddening flaw: no single run can be trusted to have found everything.
All through the year we kept hitting the same pattern: BugBot finds a bunch of issues on a PR, we resolve them, we re-trigger it to check our fixes, and to our surprise it finds more issues. Not issues caused by our fixes. Completely unrelated issues that existed in the previous commit too, which it simply chose to flag this time around. Slowly we noticed the whole team doing BugBot loops, where you keep re-running it until you get a green, because you never know whether the last pass was thorough. We did not like that unreliability.
So we asked ourselves the obvious question: what if we built our own? Our first guess was that Cursor probably runs a single model behind BugBot, so the cheapest possible experiment was to try more than one. Before building any harness at all, we started handing our PRs independently to Claude Code and to Codex and comparing what came back. The results, from Codex especially, were good enough to convince us there was something here.
That became the idea: build our own BugBot, but do not limit it to one model. Use all the flagship models available. And use them differently: not as API calls that get handed a diff, but through their own agentic coding CLIs. Claude has Claude Code, OpenAI has Codex, Gemini has the Antigravity CLI, and Cursor has the Cursor CLI for Composer. Give the same PR and the same worktree to all of them in parallel, put one orchestrator in front, and see whether that solves the pain we felt with BugBot. We call it the ensemble reviewer.
How ensemble review works
The defining choice in ensemble review is that the reviewers are not one-shot API calls. Each model runs in its own agentic CLI, with full access to the repository, not just the diff.
Handed a PR and a worktree, each reviewer goes off in its own direction. It reads the code around the diff, runs its own grep calls, walks the commit history, and compares the feature branch against what is on main, exactly as if you had asked it to review on your own machine. All three reviewers get the same prompt, but no two of them investigate the same way. Each comes back with its own list of issues, and the lists overlap. The orchestrator turns the three lists into one review. It is not a separate program; it is the same Claude model in Claude Code, given a second job. It merges the duplicates, counts how many reviewers found each issue, and decides what is worth the author's attention.
The ensemble reviewer is also a coworker, literally. It has its own GitHub account, its own email address, its own Slack and Linear identities, just like anyone else on the team, and its job description is one line: review pull requests. Every reviewer on the panel can read those accounts, but only the orchestrator can write to them. That identity is what lets it clone our repositories, post reviews under its own name, and build up a track record the team can judge it on.
We thought the rest of the work was writing a good prompt. We modeled our first review prompt on Codex's code review and used it for a few days. It was not enough: someone has to set up the three environments, collect what each reviewer finds, and coordinate everything that happens after. So the scope grew. We ended up with a reviewer prompt, a separate orchestrator prompt, and a harness that spins up the three environments in parallel and collects structured findings from each one. We added an adversarial cross-review protocol so the reviewers can challenge each other's conclusions. We wrote our own severity definitions, where P0 blocks merge, P1 should be fixed before merge, and P2 never blocks, so that noise has somewhere to go that is not the author's attention. And we kept iterating on the posting format until it read well on GitHub, survived email rendering, and made sense to the coding agents that increasingly read our reviews for us.
Why we ignore the models' confidence
Models score their own findings, and as far as we can tell those scores mean nothing. The run that convinced us was a reviewer returning zero findings at a confidence of 0.98, then voting "agree" on every finding the other reviewers had raised, each at a confidence of 1.0.
So severity comes from things the orchestrator can actually check: how many models flagged the same issue independently, whether the finding cites an exact line and a concrete fix, and whether the cited line is even part of the diff. That last one we compute from the git hunks rather than take on faith. A finding raised by two or three reviewers is nearly always real. A finding raised by one reviewer survives only when it is undeniable, with an exact location and a concrete remediation inside the changed code.
Most of what we have learned about reviewing is written into the reviewer prompt. It tells each model to read the implementation plan before reading the diff. It tells them where to spend their effort: on code that breaks the codebase's existing patterns, and on code that works at one record but falls over at a million rows, because those are the two kinds of bugs that have actually hurt us. And it lists eight conditions a finding must meet before it is allowed into the review. The simplest of the eight is a question: would the author plausibly fix this if we told them? Findings that make it through get a plain-English title, so the posted review opens with a list the engineer can understand at a glance.
This is also where the BugBot-loop pain gets solved directly. Three reviewers attacking the same commit from different directions catch most of what exists there, so the author fixes everything in one round, instead of learning about the rest one re-run at a time. On re-review the panel verifies each claimed fix at the new commit instead of reviewing from scratch, and it never re-raises something the author explicitly deferred with a reason. We learned that one the hard way, after an early second-round review re-raised five findings the author had already answered and we spent the afternoon patching the posted comments one by one. An author who deferred a finding has not missed it, and repeating it spends their trust without telling them anything new.
Making the reviewers argue (and when to skip it)
Early on we started an experiment with adversarial cross-review, and the mental model was a judge and a jury. When the reviewers come back with different opinions, it makes sense to ask each one what it thinks of what the others found, the same way a team of humans works through a pull request. You found one issue, your colleague found another, and the two of you settle which ones are real before anything reaches the judge. Mechanically, each reviewer resumes its original session, which preserves its full understanding of the diff without us re-pasting anything. It reads the merged list, including the findings it did not raise, and votes agree or disagree on every one with written reasoning. A disagreement triggers a rebuttal round, where the dissenting reviewer is reminded that the goal is to drop weak findings, not to reach agreement. If the dissent holds up with evidence, the finding is dropped.
The very first production run made this look brilliant. One model raised two issues that nobody else had caught, the other two re-read the code and confirmed both, and one of the two was a real defect that would have shipped. So naturally we ran cross-review on every PR after that. Then we audited eight random runs, comparing what went in against what came out:
Zero verdict flips in eight runs. We had overdone it at the beginning, and the data said so. When the panel already agrees, the jury room adds cost without adding signal, so cross-review now runs only when there is actual opposition among the reviews to resolve. Skipping can only err in the safe direction, because the worst case is a posted review that is slightly too severe rather than a missed blocker.
But consensus has a failure mode of its own: three models agreeing on the same misreading. So for anything marked severe, the orchestrator verifies against the real code before posting. On one security-hardening PR, the panel flagged that route matching was case-insensitive, meaning a request to /Video-Generation with a capital V walked straight past an authentication check that guarded the lowercase route. The orchestrator did not settle this by reasoning about it. It booted the exact web framework version the repository pins, sent real HTTP requests, and watched /Video-Generation come back 200 where it should have been blocked. The same probes disproved a second claim all three models had agreed on, because percent-encoded paths turned out to return 404. Consensus is a filter, not a source of truth.
Moving to the cloud
The first version of ensemble review ran entirely on a developer's laptop. With a PR ready, you would tell Claude Code to run an ensemble PR review, and it would fan out the three reviewers and come back with the findings. The natural next step was the cloud, so it could be summoned the way BugBot is summoned. Claude Code routines gave us exactly that: a sandboxed environment where the orchestrator has everything it has locally, so it clones the relevant repositories, builds the harness inside the sandbox, and runs each reviewer CLI in full. Even in the cloud, these are not one-shot API calls. Each reviewer has the same powers it has on a laptop.
/review comment to a posted review/review on a PR. Anyone on the team can do it.Cutting its fangs
The first cloud version had every power we could give it. It reviewed each PR automatically the moment one opened, the way BugBot does, and it posted binding verdicts: a request-changes from the ensemble actually blocked the merge, at one point over nothing more severe than a P2.
The team did not love either of those. Auto-review was unnecessary on small PRs where nobody had asked for it, and a bot that blocks merges felt overpowering. Under branch protection, a bot's request-changes can only be dismissed by the bot itself; a human approval does not clear it. It locked exactly one PR before we cut that fang for good. The ensemble is comment-only now, and it reviews on request.
The trigger itself went through its own evolution. It started as @pinksemble review, which we thought was clever right up until we watched the team try to spell it. We shortened it to /review, and then people simply forgot to invoke it, so now the Cloudflare Worker leaves a one-line reminder the moment a PR is marked ready for review. That nudge is what finally made usage stick. With BugBot and ensemble review running side by side on the same PRs, the team started seeing the comparisons for themselves. They liked it enough to start asking for the little things, like the emoji reactions BugBot has, which is why the trigger comment now gets 👀 when the run starts and 🚀 when the review lands. It is part of the CI pipeline now.
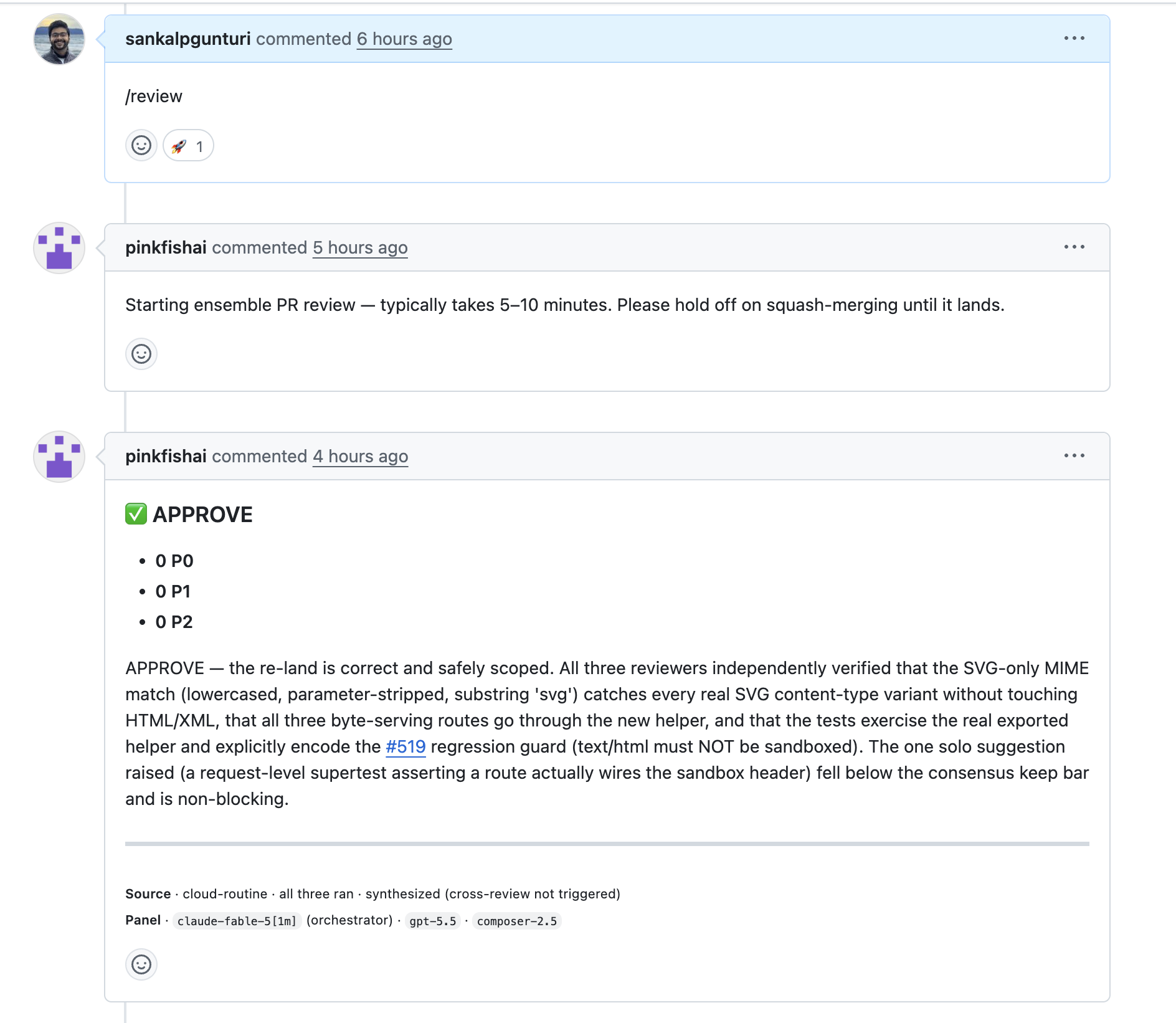
/review trigger, the start acknowledgment, and the verdict a few minutes later.
Four models, cross-review on everything, binding verdicts, auto-review on every PR. Empty folder to a working end-to-end pipeline in four commits, the same day.
We tried two different Gemini models in this seat and cut it. That alone made every round about 25% faster. The full story is a few paragraphs down.
With a CLI unreachable, the orchestrator once filled the empty seats with extra Claude sessions and posted a review titled "3 reviewers (claude ×3, simulating claude / cursor / codex perspectives)", which is one model wearing three hats. Now a preflight probe checks all three CLIs, any failed seat aborts the whole run, and the renderer refuses to print a healthy header unless all three seats actually ran.
Binding verdicts became comment-only, and review-on-every-PR became review-on-request, both at the team's ask.
The zero-of-eight audit landed, and the signature feature went behind a disagreement gate.
We gave the Gemini seat two chances, because we wanted a fourth lab on the panel. The first model we tried was gemini-3.5-flash. On one security-sensitive PR, the other reviewers were busy flagging real issues. Gemini returned zero findings, called the code "exceptionally secure", and gave itself a confidence of 1.0. Its entire review was 735 characters. So we upgraded the seat to gemini-3.1-pro-preview, which stopped the empty praise and started something worse: findings that were confidently wrong, complete with file citations. One described a "cache stampede" in code that was actually a standard single-flight pattern, where duplicate concurrent requests are collapsed into one. Posting either of those would have cost the review its credibility with the author. A reviewer that only ever agrees or invents issues adds latency, not a perspective, so we cut the seat. Today's Gemini models are not good code reviewers. The seat is still there, and when Gemini ships a model that reviews well, we will plug it back in.
The review format went through the same trimming. Early reviews were stuffed with process: panel tables, audit trails, vote counts. We found those details interesting, which is not the same as them being useful. The format we landed on is simple. The verdict comes first, then a plain-English list of the findings, each with a severity and a note on which models found it. Everything else moved out of the review and into a repository.
Evidence that ensemble review is better than BugBot
We never set out to prove we had built something better; the evidence accumulated on its own. Because BugBot runs on every push and ensemble review runs on request, both reviewers regularly read the same code, which gives us something rare: a direct comparison on identical commits. We went looking through our merged PRs for the cases that settle the question: BugBot posts its green "found no issues" check, and ensemble review, reading the same code, finds something the author then chooses to fix. It happened on at least three merged PRs, and on two of them we can pin it to the exact commit and the exact minute.
On a backend PR that recorded tool deprecations as immutable version history, BugBot greenlit the commit at 06:00. Sixteen minutes later, ensemble review flagged a P1 on the same head: the history was not actually immutable. The author fixed it, BugBot marked the fix clean at 06:29, and the ensemble then found a second P1 on the fix itself, because re-added tools were now losing their deletion history. Both were fixed before merge, and BugBot was green the whole way through.
On a data-cleanup PR, BugBot cleared the head at 00:10. The ensemble's re-review found three should-fix issues on that same head eighteen minutes later, including a path where orphaned records could never be removed.
On a frontend PR that had accumulated ten green BugBot checks, the ensemble found a P1 that two of the three reviewers hit independently from opposite ends of the code, which is exactly the corroboration signal the system is built on. The author's fix landed about an hour after the review posted.
The detail that makes this more than a scoreboard: one of the three seats in our panel is Cursor's own model, Composer, running through their CLI. We have no idea what Cursor runs behind BugBot, whether it is Composer, another model, or a mixture of several. What we do know is that our panel includes Cursor's own model and still caught what BugBot's green check missed. The edge is not a better model. The edge is the ensemble.
How it does on a public benchmark
We also ran the ensemble against an independent yardstick: Martian's offline code-review benchmark, the same public dataset other code-review tools publish scores on. It is fifty real pull requests from five large open-source projects, each with human-curated comments and an LLM judge that scores precision and recall. We ran it the way we review our own PRs: each repository cloned, each PR in a worktree, the same three reviewers and the same prompt.
The ensemble landed mid-pack, twenty-fifth of forty-two tools, with an F1 of 36.4. BugBot scored 45.5. The split is consistent across the set: the ensemble catches more of the real issues (higher recall) and also flags more that the golden set does not list (lower precision).
Two things shape that number. The benchmark hands every tool a cold repository and a diff, without the implementation plan, commit history, and codebase patterns our reviewers normally read first, which is where most of our findings come from. And cross-review, our precision filter, was switched off for the run. The benchmark also pointed at a real weak spot: the panel scored worst on Sentry's Python, missing subtle multiprocessing bugs.
How long a review takes
BugBot's run time was never something we could predict. On our own PRs we have watched it answer in two minutes and we have watched it take twenty-five, and Cursor's update this June says it has since gotten faster and cheaper. A cloud ensemble run takes eight to sixteen minutes from the /review comment to the posted review on the runs we have timed. The three reviewers run in parallel and finish in three to six minutes each; the rest is the orchestrator merging, verifying, and posting. Gating cross-review bought back the biggest chunk of that, because resuming all three sessions for more rounds was the slowest step in the whole pipeline. We are not winning a per-pass race here, and we know it. The comparison we care about is per PR: a fast reviewer you have to re-run four times is slower than a twelve-minute reviewer you run once.
The cost math
The honest version of the pricing story is that review does not have to be a separate bill. Each of the three CLIs runs through a subscription that teams already buy for everyday coding. If you already pay for those tools, an ensemble round draws on credits you have already bought rather than adding a line item, and the marginal cost of a review is low enough that cost stops being the limiting factor.
Subscriptions hide the real number though, so here is the napkin math at API list prices, using token counts logged from our own runs. A reviewer seat reads between half a million and four million tokens per round, roughly ninety percent of them cache reads, and writes five to seventeen thousand. At GPT-5.5 rates the Codex seat comes to about $2.60 per round. At Cursor's Composer rates the Composer seat stays under a dollar. At Claude's rates the Claude seat comes to about $1.70 per round on Opus 4.8. Add the orchestrator's own Claude session on top and a full ensemble round lands somewhere between $5 and $10, with a heavy PR pushing past the top of that range. For perspective, BugBot moved to usage-based pricing this June at an average of $1.00 to $1.50 per run, and Anthropic's code review for Claude Code bills $15 to $25 per review for a single model. So an ensemble round costs more than a BugBot run, and three flagship reviewers together cost less than half of what one Claude reviewer sells for.
The per-run framing also flatters BugBot, because nobody runs BugBot once. The loops we opened this post with mean two or three billed runs on an ordinary PR. Ensemble review is built to make one run enough: three reviewers cover the commit in one pass, the author fixes everything in one round, and the re-review checks the fixes instead of going hunting again. Price a review per PR instead of per run and the gap gets a lot narrower. A much larger team running this on every PR would still need to do this math properly, including subscription rate limits.
Autonomous development
This is the part that changed how we think about all of this. We now see our team giving tasks to Claude Code routines and asking them to create the PR and get it ensemble-reviewed. The routine develops the code, opens the PR, and comments /review on its own pull request, which spins up a second routine to review the work with the full panel. The first routine pulls the findings, answers them, fixes the code, and triggers the review again, and the two routines go around that loop until the review comes back clean. It is the epitome of autonomous development: by the time the PR reaches a human, it has already been through several iterations of code QA with the best models in the world, and the human's effort to review it drops accordingly. We think this loop will end up mattering more than the review itself.
Putting it in perspective
The philosophy behind ensemble review is simple: teams make better decisions than individuals. We are not after more opinions for their own sake, we are after real signal. When reviewers who worked separately flag the same problem, that is signal. When they disagree, they argue and settle it, the same way a team reaches consensus.
That signal has also been telling us something about our own process. We already guide our coding agents while they write the code, with skill files and verification gates that encode how we want things built. And three reviewers who had no part in writing the code are still finding real issues after all of that. They are not finding issues for the sake of it either: the reviewer prompt holds them to our own definition of what counts as a relevant issue, and they keep finding things that clear that bar. Each one of those findings is a blind spot in our development process, made visible. It is good that we catch them at review. But the conclusion we draw is not to invest more in the review. It is to invest more in development, so the next one of these gets caught by our own gates while the code is being written, instead of seeping through to a reviewer downstream.
A note on Gemini, since we were hard on it above: we cut it from the code panel, but this post went through a review panel of its own, Claude and Gemini, and Gemini was the stronger writer of the two. The same model we cut for code made this post more readable. Each model is good at something different.